

¡Muy buenas SoyWebmasters! Aquí David Ayala de nuevo,
En esta ocasión, me apetece hablarte de algo que siempre suscita dudas, un tema sobre el que siempre hay polémica, así que me apetece darle un poco de leña para ver qué opinas tú. Quiero hablarte sobre las diferencias entre usar Robots.txt, Meta Robots y Rel Canonical, así que vamos a empezar.
Vengo con las pilas cargadas para darte mucha caña cerebral información sobre esto, así que… ¡No te pierdas ni una sola palabra!
Índice
¿Qué es el Robots.txt

Para comenzar con buen pie, te voy a explicar de manera muy sencilla que es el robots.txt por si todavía no lo sabes o no lo tienes muy claro: “Un archivo de texto plano que debemos de alojar en el directorio raíz de nuestra web y en el cual incluiremos los estándares de exclusión de robots.”.
Entonces… ¿Para que sirve Robots.txt
Sirve para controlar el rastreo de los robots en nuestra web. Y os digo el rastreo de los robots en general, por que no solo controlamos el de Google, si no también el de otros motores de búsqueda y robots de herramientas como ahrefs, semrush o similar.
Es decir, podemos por un lado bloquear el rastreo de ciertas URLs de nuestra web a Google para ahorrar crawl budget, y por otro lado podemos bloquear el rastreo de los robots de ciertas herramientas para que no detecten información como los links de nuestras webs (esencial para las PBN por ejemplo).
Robots.txt sirve para controlar el rastreo de los robots en nuestra web. Clic para tuitear¿Y para qué No sirve Robots.txt?
Usar robots.txt no hará que se elimine una URL de Google, solamente impediremos que la rastree, pero no que la indexe.
Robots.txt no sirve para eliminar una URL de Google. Clic para tuitearBloqueo de archivos de recursos
Tenemos que tener cuidado a la hora de limitar el rastreo de directorios en nuestras webs, ya que podemos bloquear por ejemplo el rastreo de imágenes que podrían posicionar en Google Images y de las que podríamos obtener visitas.
Del mismo modo también debemos evitar bloquear el rastreo de ficheros javascript y CSS.
Si tenemos que bloquear un directorio completo, recuerda hacer “allow” de los subdirectorios donde tengas esos recursos.
¿Qué es el meta robots?
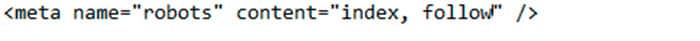
Para comenzar, meta robots es una meta etiqueta que debe de ser incluida entre las etiquetas “head” de nuestro código HTML.
¿Para qué nos sirve Meta Robots?
El meta robots sirve para indicar a los robots de los buscadores como indexar las urls y como rastrearlas.
Es decir, con esta etiqueta indicaremos si queremos que esa URL se indexe o no en el buscador e indicaremos si queremos que la rastree.
Meta Robots sirve para indicar si indexar o no una URL. Clic para tuitearY por otro lado, para qué No tiene utilidad el Meta Robots
En muchas ocasiones veo como la gente dice que usando meta robots noindex, al no indexar esa URL Google, vamos a ahorrar crawl budget, pero esto no es cierto.
Es verdad que conseguiremos que deje de indexarla Google y desaparezca de sus resultados, pero Google puede seguir rastreandola, y es más… ¡Lo hará! Sobre todo si recibe links de otras webs que hagan que llegue Google a ella.
Para asegurarnos el evitar el rastreo y ahorrar crawl budget de verdad, debemos de usar Robots.txt.
Con meta robots no index no ahorraremos crawl budget. Clic para tuitear¿Cómo interpretamos meta robots?
index, follow -> indexame y sigueme
index, nofollow -> indexame pero no me sigas
noindex, follow -> no me indexes pero sígueme
noindex, nofollow -> ni me indexes ni me sigas
Es muy importante tener en cuenta el atributo follow o nofollow en el meta robots, sobre todo a la hora de dejar enlaces en otras webs o a la hora de comprar enlaces, ya que si dejamos o compramos un link en una URL que tenga meta robots noindex, Google no rastreará los links que tenga esa web y por lo tanto nos servirá de poco ese link.
¿Qué es rel canonical?
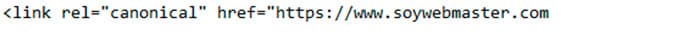
Rel canonical es un elemento de enlace, es decir, es un elemento que indica cual es la URL original de un contenido.
Esto se suele utilizar por ejemplo en los ecommerce cuando generamos URLs con parámetros que realmente son solo una versión de la original sin parámetros.
Vale, pero… ¿Para qué sirve rel canonical?
Simplemente sirve para eso, para indicar cual es la versión original y para indicar cual es la “copia”.
Es decir… Rel Canonical sirve de poco, y en el siguiente apartado te diré por qué.
Por qué no es útil el Rel Canonical
Rel canonical no sirve para desindexar URLs. Clic para tuitearEs decir, por mucho que usemos rel canonical, seguiremos indexando en Google esas URLs copia de otras.
Rel canonical no sirve para ahorrar crawl budget. Clic para tuitearPor mucho que usemos rel canonical, Google seguirá rastreando esas URLs.
Conclusiones Personales
Y por último vamos a lo que a mi me gusta, a dar mi opinión personal sobre este tema. Y es que en definitiva se podría decir que rel canonical es un atributo un tanto absurdo, ya que no nos resuelve prácticamente ningún problema el usarlo.
Sin embargo si sabemos usar bien meta robots y robots.txt, sí vamos a ser capaces de solucionar muchos de los problemas de nuestras webs.
Aunque obviamente, lo ideal sería no tener que usarlos nunca ya que no dejan de ser “parches”, y desde luego cuanto menos los necesitamos, significará que mejor construida está nuestra web, pero siendo realistas eso es algo prácticamente imposible para la mayoría.
Así que nada, espero que os haya gustado el artículo y espero sobre todo que me dejes en comentarios lo que opinas tú sobre este tema, tanto si estás de acuerdo como si no.
Como complemento os dejaré el link hacia este otro artículo que hice anteriormente sobre como eliminar definitivamente las URLs de Google, que seguro será un gran complemento.
¡Nos vemos en el próximo artículo!
RECIBIR NOVEDADES POR EMAIL
