

¡Buenas Soywebmasters!
¡Aquí David Ayala de nuevo!
En esta ocasión vengo a hablarte sobre algo en lo que algunas personas he visto que tienen dudas o no les queda del todo claro. Además me apetecía hablar sobre este tema, así que aquí está, un post sobre las diferencias entre rastreo e indexación en Google.
Así que sin más… ¡Comenzamos!
Índice
¿Qué es el rastreo de cara a Google?
Google es un buscador y como tal necesita mostrar resultados de páginas web para las búsquedas realizadas por sus usuarios. Estos resultados los encuentra rastreando la red, es decir saltando de unos enlaces a otros.

De igual manera Google no solo rastreará esas URLs una única vez pues lo hará más veces posteriormente para comprobar si el contenido ha cambiado, se ha añadido nuevo, sigue existiendo, etcétera.
¿Qué es la indexación de cara a Google?
Que Google rastree una URL no quiere decir que la indexe pues tras rastrearla deberá analizarla y después decidir si indexarla o no.
Simplificándolo todo, se podría decir que Google funciona mediante keywords e intenciones de búsqueda, es decir para poder encontrar cualquier URL el usuario debe introducir una keyword en el buscador, por lo tanto la indexación de una URL lleva implica la asociación de keywords o intenciones de búsqueda a la misma. Evidentemente estas podrían variar con el tiempo.
Cómo evitar rastreo de Google
Para evitar el rastreo de una URL por parte de Google debemos utilizar el fichero robots.txt.
En este fichero utilizaremos la directiva disallow para que Google no pueda rastrear una zona en concreto de nuestra web. Al tratarse de una directiva cuando Google lea nuestro robots.txt tendrá que hacerle caso sí o sí.
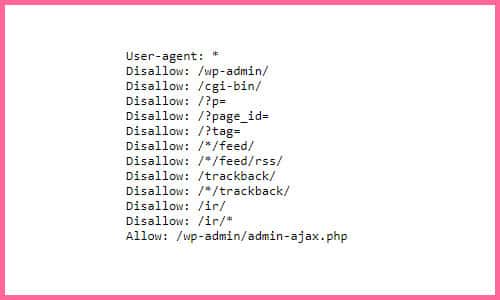
Bloquear el rastreo de una URL no implica bloquear su indexación, es decir, puede que Google no lea el contenido de esa URL al no poder rastrearla pero eso no quiere decir que no sepa de la existencia de esa URL debido a enlaces tanto internos como externos. Por lo tanto, una URL que esté bloqueada para rastreo podrá ser indexada por Google.
Cómo evitar indexación en Google
Para evitar la indexación de una URL en Google tenemos que utilizar la meta etiqueta robots noindex.

Esta etiqueta es una directiva, es decir, a penas Google la vea le tiene que hacer caso obligatoriamente (no es una opción).
Si la URL estaba ya indexada en Google, evidentemente no se desindexará de manera instantánea pues primero Google tiene que leer esa etiqueta.
Podemos esperar hasta que Google pase por esa URL o intentar acelerarlo de una de las dos siguientes maneras:
-En Google Search console introduces la URL en el inspector de URLs, le das a “probar URL publicada” (este paso es más una manía mía) y luego a “solicitar indexación”.

-Como con el noindex realmente queremos eliminar esa URL del índice podemos directamente en Google Search Console ir a la opción de “retirada de URLs” y solicitar la eliminación de la misma.

Cuando bloquear el rastreo de Google
La limitación del rastreo de cara a Google se realiza para evitar gastar recursos del buscador y presupuesto de rastreo “a lo tonto”.
Esto puede ser útil para limitar al bot de Google a rastrear ciertas URLs como las de parámetros o incluso para casos concretos como por ejemplo si Google siguiera rastreando zonas que ya no existen de nuestra web. Siguiendo ese mismo ejemplo, si antes existía una sección en nuestra web que ahora no y esa sección no la hemos redireccionado a ninguna parte y tan solo la hemos eliminado y comprobamos en los logs que Google pasado un tiempo sigue rastreando una y otra vez esas URLs (podría ser debido a enlaces externos), una solución sería bloquear el rastreo de esa/s URL/s.
Cuando bloquear la indexación de Google
Por norma general evitaremos la indexación de URLs que no queramos posicionar, es decir URLs que realmente no tengan ningún valor de cara a SEO pues si no va a posicionar en Google ¿Para que queremos que esté ahí?
De igual manera, las URLs que puedan ser consideradas como contenido duplicado, thin content, etcétera que por algún motivo no podamos eliminar o por que debamos dejarlas de cara a usabilidad de los usuarios.
Bloqueo de rastreo e indexación
Un error que he visto en muchas ocasiones es aplicar meta robots noindex y disallow de robots.txt para un directorio o una URL. Tras un tiempo se preguntan, ¿Por qué esas URLs no las está eliminando Google? ¡Google hace lo que le da la gana!
En esos casos es normal que no las elimine ya que para poder hacerlo debe ver la etiqueta meta robots noindex, pero… ¡No puede verla por que le has bloqueado el rastreo por robots.txt!
¡Cuidadín!
Conclusiones
Como has podido comprobar rastreo e indexación son dos cosas muy diferentes, por lo tanto es importante saber diferenciar la una de la otra para poder actuar de la manera más correcta según nuestras necesidades.
Ahora me gustaría que me dejaras tu opinión, me contases situaciones curiosas que te hayan ocurrido o en definitiva… 👉 ¡LO QUE ME QUIERAS CONTAR! 👈
RECIBIR NOVEDADES POR EMAIL

Hola David, muy interesante e importante conocer esta diferencia en estos conceptos.
Yo tengo la duda de si tienes un una url con idioma ingles por ejemplo que te está generando contenido duplicado o thin content y quieres desindexar ese contenido. Lo puedes hacer desde la raiz con robotstxt o tienes que ir pidiendo en search console la eliminación de cada url? Gracias. Un saludo
Buenas Raúl! Si la URL es la versión inglesa con utilizar hreflang para indicarlo no deberías tener mayor problema. En cuanto a que quieras desindexarlo por cualquier otro motivo no sería con robots.txt pues ahí solo bloqueas rastreo, tendrías que utilizar la etiqueta meta robots noindex.
Hola David, excelente aporte. El que explicarás cuando se debe usar uno y cuando otro, deja las cosas muy claras.
¿A partir de cuantas URL podrías considerar relevante el presupuesto de rastreo? Tengo sitios con menos de 50 url y me parece que no es factor, ¿o si?
Saludo!
Buenas Marco!
Cuando son webs tan pequeñas no debe preocuparte tanto aspectos como presupuesto de rastreo 🙂
Hola David, excelente aporte. El que explicarás cuando se debe usar uno y cuando otro, deja las cosas muy claras.
¿A partir de cuantas URL podrías considerar relevante el presupuesto de rastreo? Tengo sitios con menos de 50 url y me parece que no es factor, ¿o si?
Saludo!
Buenas Marco!
Cuando son webs tan pequeñas no debe preocuparte tanto aspectos como presupuesto de rastreo 🙂
Excelente post, vamos a compartirlo con mis colegas.
Saludos!
Excelente post, vamos a compartirlo con mis colegas.
Saludos!
Para mí lo más importante, y lo que esperaba leer en tu explicación es la aclaración del último apartado "Bloqueo de rastreo e indexación" cuando alguien bloquea en el archivo robotx.txt para una página que tiene que estar en "noindex". Este es un fallo muy común. Buen post David!
Excelente post como siempre…
Saludos